需求
起因是我看到一款是基于PHP写的豆瓣插件,所以我也想同步我的豆瓣影单以及书单到博客网站上,但是豆瓣并没有提供这样的接口允许你获取到自己的影单以及书单数据。那没办法只能自己爬数据了,刚好我对爬虫又有点研究,这点实现起来不难。
为什么要集成scrapy
实际上不用scrapy来爬取,纯python也能实现,但是我坚持在django项目里集成scrapy,好处有三:
- 保证整个项目的完整性,所有的内容都放在当前django项目下,便于后期迁移。
- 利用
scrapy-djangoitem可以很好的通过django的orm完成数据存储,因为后台读取的时候也是基于model来操作的,也避免通过执行sql插入语句来完成数据插入了。- 有了scrapy这个爬虫框架,后期站点再需要爬取什么的时候,直接在该框架里面再添加爬虫即可。
如何解决定时同步
那同步的问题怎么解决呢?我想到利用celery的定时任务定时执行爬虫不就行了,一开始我是直接将
scrapy crawl xxx写在一个函数里面,然后定时执行该函数,发现行不通,会提示scrapy命令找不到,可能是因为我的scrapy工程也放在了我的博客项目根目录下。后来我就找有没有其他的启动scrapy爬虫的方法,百度了许多资料但是和django放一起好像都不行,最后让我发现了scrapyd,通过scrapyd的api也可以执行scrapy爬虫的啊,而且scrapyd还可以部署爬虫项目,这样我的博客后期如果再需要爬取什么的话,到时候部署起来也方便。
scrapy简介
scrapyd是用来管理scrapy的部署和运行的一款服务程序,scrapyd让我们可以通过一个简单的Json API来完成scrapy项目的运行、停止、结束或者删除等操作,当然它也可以同时管理多个爬虫。这样的我们部署scrapy时就比较方便的控制爬虫并且查看爬虫日志。
scrapyd的安装
pip install scrapyd
pip install scrapyd-client
windows上需要注意的
正常安装完scrapyd,linux下是没问题的,但是windows下还需要实现一个bat脚本,因为在python安装目录下scripts文件里有一个scrapyd-deploy(无扩展名),这个文件是启动文件,但是在windows下不能运行,只能在linux运行。在上述的scrapyd-deploy同级目录下创建一个名字为scrapyd-deploy.bat的文件,内容如下:
@echo off
"F:\develop\Python\envs\blog\Scripts\python.exe" "F:\develop\Python\envs\blog\Scripts\scrapyd-deploy" %1 %2 %3 %4 %5 %6 %7 %8 %9
注意以下两点
- 两个路径必须是双引号并且两个路径之间有空格;
- 第一个路径填写python.exe的路径;
- 第二个填写上述的scrapyd-deploy文件的路径;
scrapy部署项目
在当前博客根目录下新建scrapyd文件夹(用来部署scrapy项目)
编辑scrapy项目下的scrapy.cfg文件
[settings] default = blog.settings [deploy:test] url = http://localhost:6800/ project = blogdeploy后跟的是此处部署名称,随便取即可,project是项目名不一定要是scrapy项目名,其他名也可以。
在terminal界面切换到scrapyd目录下执行命令
scrapyd
只有切换到了scrapyd的目录下这样部署的时候内容才会存储在该目录下发布工程到scrapyd(这里的参数就必须要要跟cfg里面配置一致)
scrapyd-deploy test -p blog- target:部署名
- project:项目名
在scrapyd目录下会多个三个文件夹

浏览器地址栏输入
http://127.0.0.1:6800/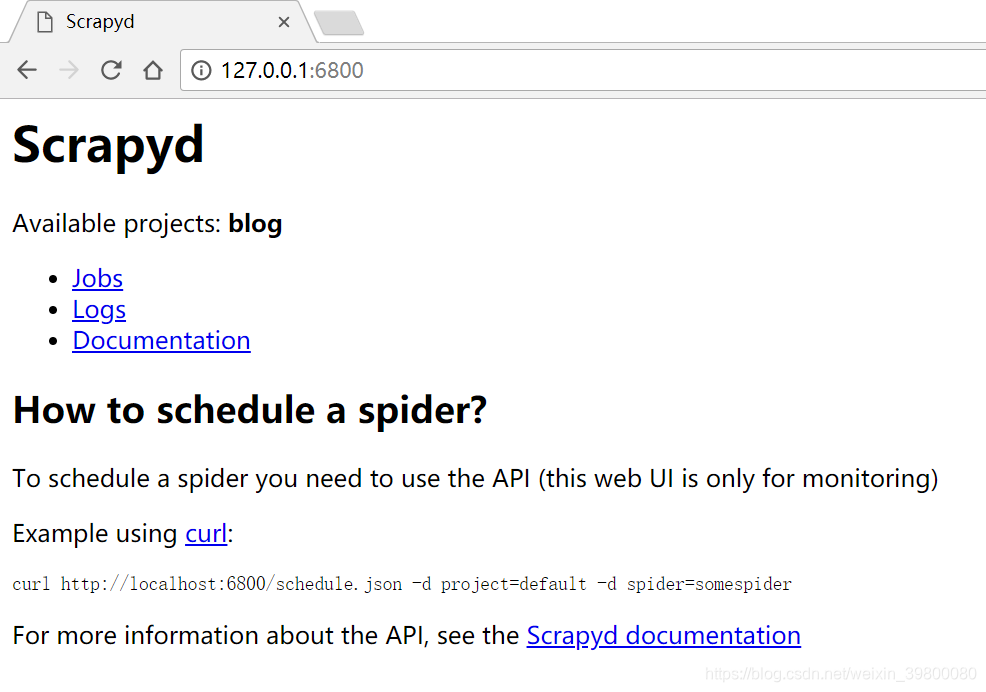 可以看到可用项目有一个blog,说明部署成功了。
可以看到可用项目有一个blog,说明部署成功了。运行爬虫
curl http://localhost:6800/schedule.json -d project=blog -d spider=book从上面的界面点击jobs显示如下
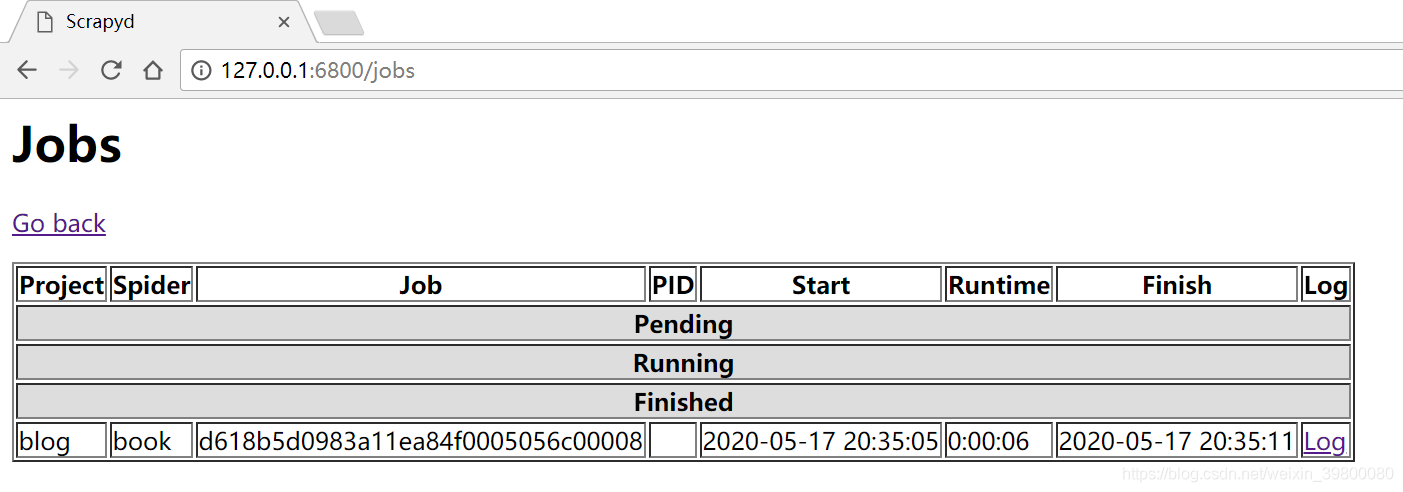 可以看到有一个爬虫已经运行完成了,这是我爬取豆瓣书单的一个爬虫,点击该爬虫最后的logs可以看到内容如下:
可以看到有一个爬虫已经运行完成了,这是我爬取豆瓣书单的一个爬虫,点击该爬虫最后的logs可以看到内容如下: 本质上内容没有乱码,因为我看了我存到数据库的内容是正常的。因为scrapyd针对logs页面请求响应头没有设置编码格式,导致内容乱码,网上解决方式也有几种,我这里直接用了chrome修改页面编码插件,改变编码为utf-8,结果如下:
本质上内容没有乱码,因为我看了我存到数据库的内容是正常的。因为scrapyd针对logs页面请求响应头没有设置编码格式,导致内容乱码,网上解决方式也有几种,我这里直接用了chrome修改页面编码插件,改变编码为utf-8,结果如下: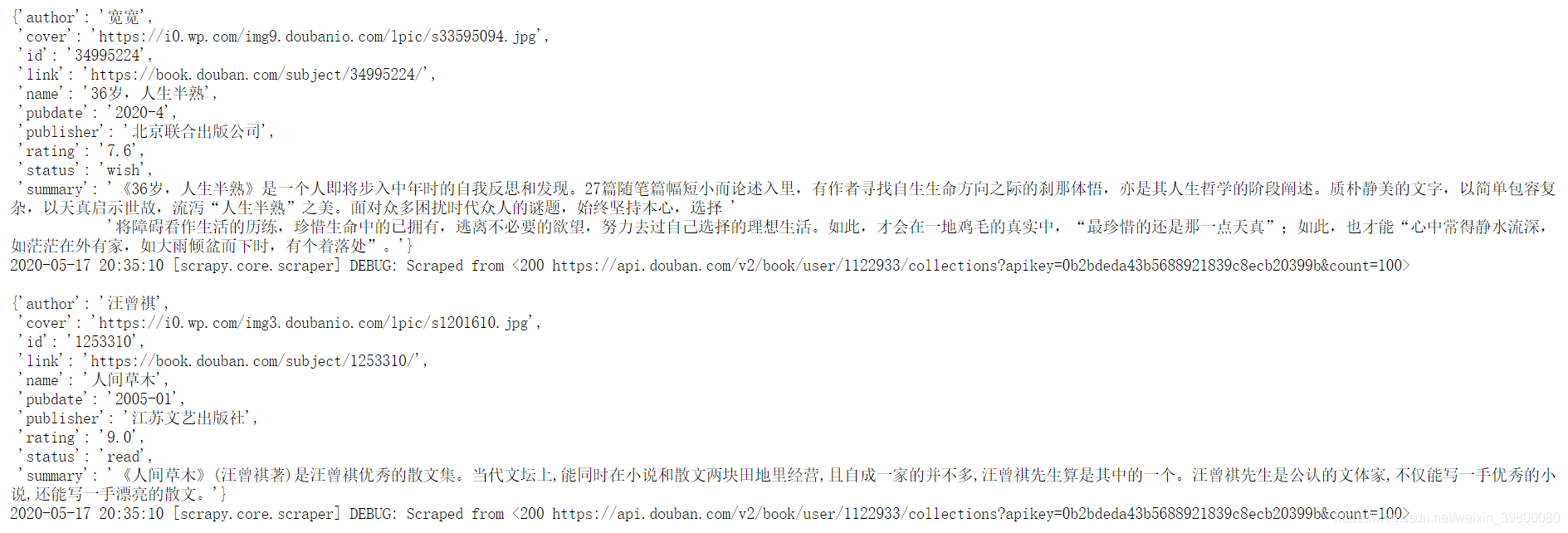 其实也可以通过post-man等restAPI访问请求,内容也不会乱码的。
其实也可以通过post-man等restAPI访问请求,内容也不会乱码的。
scrapyd管理API
- 获取状态
http://127.0.0.1:6800/daemonstatus.json
- 获取项目列表
http://127.0.0.1:6800/listprojects.json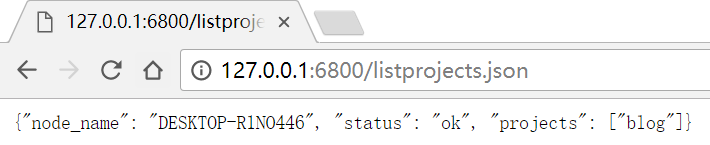
- 获取某个项目下已发布的爬虫列表
http://127.0.0.1:6800/listspiders.json?project=myproject
获取项目下已发布的爬虫版本列表
http://127.0.0.1:6800/listversions.json?project=myproject
- 获取爬虫运行状态
http://127.0.0.1:6800/listjobs.json?project=myproject
启动服务器上某一爬虫(需要是已部署到服务器的爬虫)
curl语句curl http://localhost:6800/scedule.json -d project=项目名称 -d spider=项目名称python语句
import requests req=requests.post(url="http://localhost:6800/schedule.json",data={"project":"blog","spider":"book"})删除某一版本爬虫
curl语句import requests http://localhost:6800/delproject.json -d project=scrapy项目名称 -d version=scrapy项目版本号python语句
import requests req=requests.post(url="http://localhost:6800/delproject.json",data={"project":"项目名","version":"项目版本号"})删除某一工程,包括该工程下的各版本爬虫
curl语句import requests http://localhost:6800/delproject.json -d project=scrapy项目名称python语句
req=requests.post(url="http://localhost:6800/delproject.json",data={"project":"项目名"})取消爬虫
curl语句import requests http://localhost:6800/cancel.json -d project=scrapy项目名称 -d job=jobIDpython语句
import requests req=requests.post(url="http://localhost:6800/cancel.json",data={"project":"项目名","job":"jobID"})celery定时执行爬虫
在根目录下任意应用目录下新建tasks.py文件
from __future__ import absolute_import from celery import shared_task import requests @shared_task def main(): req=requests.post(url="http://localhost:6800/schedule.json",data={"project":"blog","spider":"movie"}) print(req.text)切换到scrapyd部署目录下
cd scrapyd启动scrapyd
scrapyd接下来只要设置好定时任务定时执行刚刚的tasks.py里面的main方法即可关于如何配置celery定时任务可以参考我另外一篇关于文章django集成celery。
另外我想说的是上面的只适合在本地执行,并且需要注意一定的顺序,需要开好几个terminal分别运行celery-worker,celery-beat,scrapyd,如果用到了redis,还得再开一个redis,我目前博客已经部署上线完毕,并且豆瓣影单书单同步线上测试正常,通过supervisor来管理这些命令很方便。还有的就是关于scrapyd我也没有开启外网访问,也是为了安全性考虑,也就是说不可以通过外网部署到scrapyd目录下,不过没事,如果新增了其他爬虫,完全可以本地部署完毕,上线覆盖掉原来scrapyd目录下的内容,重启下scrapyd即可。

